
What Attention Dose Not Look At Is All You Need
Published:
Motivation
- This post proposes a hypothesis about how BERT learns syntactic representations, mainly based on an analysis of BERT’s attention (Clark et al., 2019).
- As shown in Figure 1, attention heads often focus on special tokens: early heads attend to [CLS]; middle heads attend to [SEP]; deep heads attend to periods and commas.
- Inspired by this, we suppose there are three phases of heads focus on different representations.
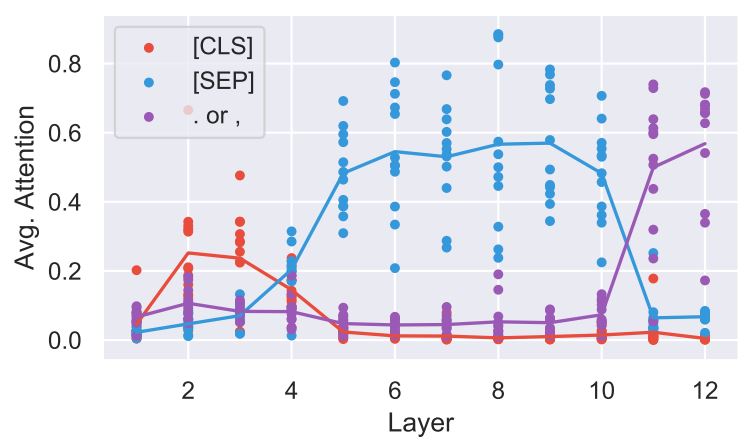 Figure 1: The average attention a particular BERT attention head puts toward a token type (Clark et al., 2019).
Figure 1: The average attention a particular BERT attention head puts toward a token type (Clark et al., 2019).
Content
- For a better understanding, we first discuss what makes tokens special.
- Then we present solid results from the analysis as well as our explanations to them in each phase.
- Lastly, we present a holistic view of attention: what attention does not look at is all you need.
Special Tokens
- High token frequency makes learning easier and earlier, which separates frequent tokens from the others.
- Then, constant-relation frequency of frequent tokens differentiates outsiders from insiders:
- Insiders (e.g., “the”, “be”, “to”) often have simple and constant relations. For example, articles (a/an/the) are often related to the immediately following word.
- Outsiders ([CLS], [SEP], periods, commas, and [MASK]) can hardly have constant relations with other tokens.
- When looking into the outsiders, we find that they can be separated into three types:
- [CLS] is a hunter, since it has broad attention due to the Next Sentence Prediction (NSP) task.
- [SEP] locates at the end of sentences, which makes it a haven for tokens that need to lie low. Details in phase two.
- Typically, the “sentences” referred to by BERT are much longer than single sentences. Periods and commas are separators for traditional sentences inside the “sentences”. They locate at flexible positions like drifters.
- [MASK] is born to fulfill the Masked LM task. Since it shares the same charactristics with periods and commas, it is also a drifter. In BERT’s view, it is the randomly selected drifters ([MASK]) that are responsible for the Masked LM task. Thus, Masked LM will motivate all drifters’ attendance.
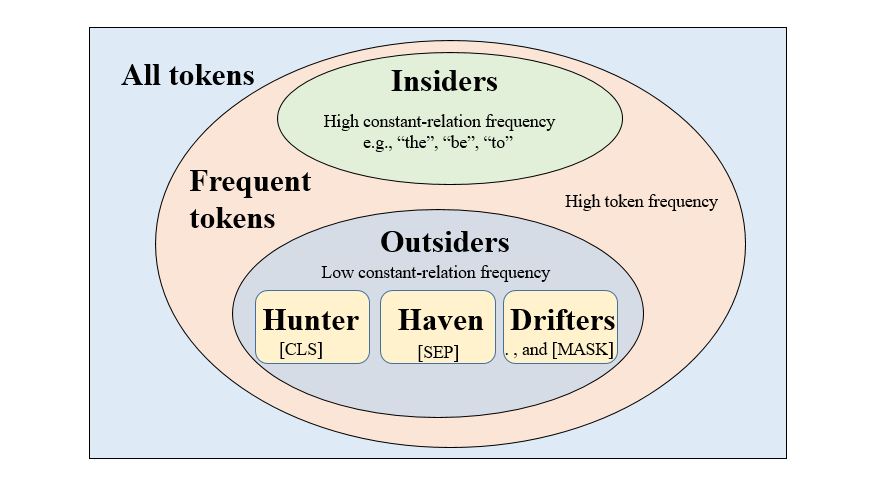 Figure 2: Relationship of tokens in Venn diagram.
Figure 2: Relationship of tokens in Venn diagram.
Phase One
- Hypothesis: Usage of tokens is the main concern for early heads.
- Solid Results:
- In lower layers, some attention heads have very broad attention.
- Attention to [CLS] is relatively higher than that to other tokens.
- Explanations:
- Attention heads attend broadly to get information on tokens.
- [CLS] is often attended, because it is a hunter. The heads attend to it for information on other tokens instead of the hunter itself.
Phase Two
- Hypothesis: High constant-relation frequency makes attendance from insiders the main concern for middle heads
- Solid Results:
- Attention to [SEP] becomes high in layers 5-10 as shown in Figure 1. Meanwhile, the importance of it becomes very low as shown in Figure 3.
- While no single attention head performs well at syntax “overall”, attention heads specialize to specific dependency relations (e.g., pobj, det, and dobj), especially for heads from layers 4-9.
- It is often the case that the dependent attends to head word rather than the other way around.
- Explanations:
- To highlight attendance from insiders, other tokens need to avoid attending to the same tokens that insiders may attend to. Since insiders often attend to tokens in the neighborhood, [SEP] at the end of sentences (usually far away from insiders) becomes a haven for those tokens to lie low.
- Because insiders’ relations are usually specific, attention heads will specialize to specific dependency relations.
- Since insiders are often dependents, it is more often the dependent attends to head word than the other way around
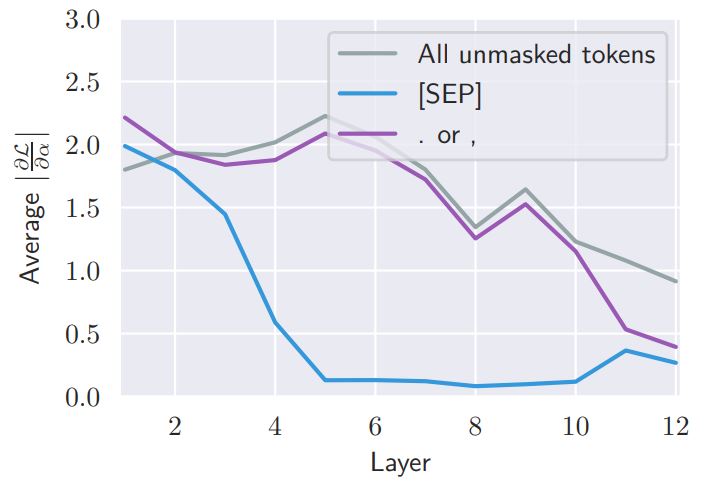 Figure 3: Gradient-based feature importance estimates for attention to [SEP], periods/commas, and other tokens (Clark et al., 2019).
Figure 3: Gradient-based feature importance estimates for attention to [SEP], periods/commas, and other tokens (Clark et al., 2019).
Phase Three
- Hypothesis: Masked LM and high token frequency make attendance from drifters the main concern for deep heads
- Solid Results:
- Attention from [CLS] is obviously broader than the average in the last layer.
- Over half of attention focuses on periods and commas in the last two layers.
- Explanations:
- [CLS] attends broadly to aggregate a representation to fulfill NSP task. However, its influence on attention heads is very limited, since it is less frequent than drifters.
- To highlight attendance from drifters, other tokens need to avoid attending to the same tokens that drifters may attend to. Since drifters are motivated to attend to other tokens, they themselves become havens for those tokens to lie low.
- Since tokens in the same part of sentences will contribute the most to predictions of [MASK], drifters are motivated to attend to tokens in the same part of sentences. Deep heads may learn finer-grained segment as a by-product since most drifters are traditional separators (periods and commas).
Conclusion
- By comparing Figure 1 and 3, it is shown that the importance of attention to the tokens negatively correlates to average attention to them.
- We suggest that what attention does not look at is all you need: early heads attend to [CLS] because they need the information on other tokens; middle heads attend to [SEP] because they need to highlight attendance from insiders; deep heads attend to periods and commas because they need to highlight attendance from drifters.
- We also suggest that each phase of attention heads learn a certain syntactic representation: early heads learn part of speech of tokens; middle heads learn dependency between tokens; deep heads learn finer-grained segment.